This post was written by guest blogger, Dr. Grant Walker. Dr. Walker is a C-STAR postdoctoral scholar located at the University of California at Irvine. In this post, he describes a study he recently published in the journal Psychological Assessment. You can find the abstract here. Read on for a summary of his work!
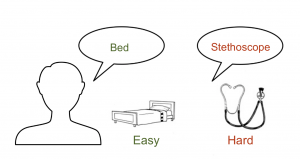
Clinicians need the right tools to understand and treat speech and language impairments. Clinicians often use a picture naming test to assess speech and language production in people with aphasia. The number of correct responses is simple to calculate and shows how well someone performs on that task. However, some test items may be harder to name than others. For example, it may be harder to say names like ‘stethoscope’ than names like ‘bed,’ so it is important to know how item difficulty affects performance.

Furthermore, picture naming is a complex process that involves these abilities:
- Identifying what the picture is (visual recognition)
- Remembering the name of the word (word retrieval)
- The ability to articulate (pronounce) the word
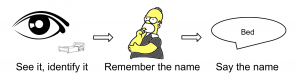
 People with aphasia may have difficulty with any of these steps, so identifying the specific type of problem can help clinicians specialize their therapy.
People with aphasia may have difficulty with any of these steps, so identifying the specific type of problem can help clinicians specialize their therapy.
To know how difficult a test item is, we need to know how different people respond to it. This is one of the reasons that participation in research is so important, because it helps us fine-tune our tests to achieve the most precise measurements possible.
We recently published a paper in the journal Psychological Assessment(Walker, Hickok, & Fridriksson, 2018). We examined 63,875 picture naming attempts from 365 participants with aphasia. The information we gathered helped us develop a statistical model that describes how participant abilities and the difficulty of each test item play a role in successful picture naming attempts.
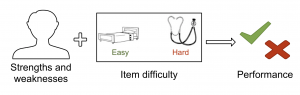
Statistical models help researchers understand data. In aphasia research, statistical models help us understand how our research can be used to help improve aphasia testing and treatment. We checked that our statistical model was capturing the important patterns among the different picture naming responses. To do this, we compared our statistical model’s predictions of naming outcomes with other statistical models.
We found that our statistical model gave better predictions, because it was able to focus on the relevant information about the different stages of picture naming. For example, word finding abilities were strongly related to scores on other tests such as word-to-picture matching. The ability to correctly produce the sounds of the words was related to scores on speech repetition tests.
We made the statistical model available through a new website (www.cogsci.uci.edu/~alns/MPTfit.php), so researchers and clinicians can use our new understanding of picture naming difficulty to improve their assessments of abilities.
Our plan is to continue refining our models and measurements by collecting more data that will help us understand the different ways that people may respond to tests for aphasia, and how these responses may change with therapy over time.
Thanks to Pixabay.com for the clipart